Cloudera CDH/CDP 및 Hadoop EcoSystem, Semantic IoT등의 개발/운영 기술을 정리합니다. gooper@gooper.com로 문의 주세요.
출처 : http://www.cyworld.com/duetys/14467821
3-1. 일반정보<?XML:NAMESPACE PREFIX = O />
HBase에 접근하는 주요 client 인터페이스는 HTable 클래스이다.
org.apache.hadoop.hbase.client 패키지 à Class HTable
각, 메소드의 SUMMARY /
DETAIL 정보는 아래 URL을 참조하면 된다.
http://hbase.apache.org/apidocs/org/apache/hadoop/hbase/client/HTable.html
[일반사항]
- 데이터 변경하는 로우 단위 작업은 원자성이 보장 (모든 read & write), 자세한 설명은 ch8
- HTable 인스턴스 생성 시 비용 발생하여 단 한번만 생성
- 스레드 당 하나씩 생성 하여 재사용 한다. (여러 개 필요 시에는 HTablePool 사용 287page)
3-2. CRUD 기능
- CREATE, READ, UPDATE, DELETE는 HTable Class에서 제공된다.
3.2.1. Put 메소드
- 단일 로우 vs 여러 로우 대상으로 동작하는 기능으로 분리
1). 단일 Put
- Put 인스턴스를 생성하기 위해서는 로우키를 제공해야 한다.
- 로우키 타입은 java 데이터 타입인 바이트배열타입으로 저장됨
- put 할때 타임스탬프를 지정가능하고 명시 하지 않으면 리전 서버의 시스템 date를 사용한다.
- hbase의 기본설정은 하나의 값 버전을 세개까지 저장한다. ( scan ‘테이블명’, {versions => 3} )
[샘플]
|
public class PutExample { public static void main(String[] args) throws IOException { Configuration conf = HBaseConfiguration.create(); ➊ 필요한 설정 객체 생성 HTable table = new HTable(conf, "testtable"); ➋ 인스턴스화한다. Put put = new Put(Bytes.toBytes("row1")); ➌ Put 객체 생성 put.add(Bytes.toBytes("colfam1"), Bytes.toBytes("qual1"),Bytes.toBytes("val1")); ➍ colfam1:qual1 put.add(Bytes.toBytes("colfam1"), Bytes.toBytes("qual2"),Bytes.toBytes("val2")); ➎ colfam1:qual2
table.put(put); ➏ testtable이라는 hbase 테이블에 저장 } } |
2). Keyvalue 클래스
: ROW 단위가 아닌 특정 셀 단위의 모든 정보를 반환한다.
: 시스템 내부 용도로 개발되었음. 주로 KEY 데이터간의 비교 / 검증 / 복제 등에 사용
: 대부분 ROW단위로 처리 되기에 실제 어플에서 사용할 경우는 거의 없을 것으로 판단됨.
3). 클라이언트 측 쓰기 버퍼
- round-trip-time을 줄이기 위하여 RPC를 최소화 해야 한다.
- HBase API는 client단에 쓰기 버퍼를 제공함( Default는 비활성화)
- table.setAutoFlush(false) 로 버퍼 enable
- Default Buffer size : 2MB, hbase-site.xml 설정으로 일괄 적용 가능
|
<property> <name>hbase.client.write.buffer</name> <value>20971520</value> </property>
|
- Buffer flush
명시적 : flushcommits() 사용
묵시적 : setAutoFlush(true) 일 경우 put 실행시, setWriteBufferSize() 실행 시,
HTable의 close() 메소드 사용 시 묵시적인 flush 발생 됨
- 클라이언트 버퍼는 cell 데이터가 작을 경우 효과를 볼 수 있음.
4). Put 리스트
- 연산을 일괄로 한데 묶어서 처리 함, SQL의 INSERT SELECT 구문이라고 생각
- 리스트 기반의 입력은 서버 측에서 입력 연산이 적용 되는 순서를 제어 할 수 없음
데이터 입력 순서를 보장해야 하는 경우 작게 나눈 후 Write cache를 명시적으로 flush 필요함
5). 원자적 확인 후 입력 연산 ( checkAndPut )
- 조건 확인 성공 시 입력 연산이 실행 됨 실패하면 연산은 버려진다.
- A 세션이 작업하는 동안 B세션이 동일한 작업을 실행하여 데이터 변경이 없음을 확인 후 적용
- 동일한 로우에서만 확인하고 수정한다. (원자성은 로우 하나에만 보장됨)
3.2.2. Get 메소드
- 단일 로우 vs 여러 로우 대상으로 동작하는 기능으로 분리
1) 단일 GET
- 특정 로우 하나를 대상으로 수행되지만, 로우 내에서는 컬럼/셀 제한 없음
- 버전개수는 1로 최근 값만 리턴 받음 / setMaxVersions() 매소드를 통하여 지정가능
|
Configuration conf = HBaseConfiguration.create(); ➊ 인스턴스 생성 HTable table = new HTable(conf, "testtable"); ➋ 테이블 참조를 인스턴스화 Get get = new Get(Bytes.toBytes("row1")); ➌ row1 인 GET 인스턴스 생성 get.addColumn(Bytes.toBytes("colfam1"), Bytes.toBytes("qual1")); ➍ get instance에 컬럼추가 Result result = table.get(get); ➎ hbase에서 row1의 colfam1:qual1 컬럼을 읽어 들인다. byte[] val = result.getValue(Bytes.toBytes("colfam1"), Bytes.toBytes("qual1")); ➏ 컬럼의 값을 가져온다. System.out.println("Value: " + Bytes.toString(val)); ➐ 자바 데이터타입을 string으로 변환하여 결과 출력
|
2) Result 클래스
- get() 메소드를 통하여 데이터를 읽어 들일 때 get 조건에 만족하는 모든 셀을 담고 있는
Result 클래스의 인스턴스를 반환한다.
- 서버에서 반환한 모든 컬럼패밀리, 퀄리파이어, 타임스탬프 접근 수단을 제공한다.
3) GET List
- 하나의 요청으로 하나 이상의 로우를 요청 시 사용됨
- get 인스턴스와 동일한 배열을 반환하던지 예외발생 둘 중 하나로만 동작한다.
- API에서 일괄처리 진행 중에 부분 실패를 처리하는 방법은 batch() 메소드를 사용해야 한다.
3.2.3. Delete 메소드
1) 단일 delete
- delete 클래스를 생성하려면 삭제 대상 row key를 입력해야한다.
- rowlock 파라미터를 추가 선택하여 동일한 로우를 두번 이상 변경하고자 할 때 사용자 자신의 락을 설정 한다.
- 전체 패밀리 및 그에 석한 모든 컬럼 삭제 / 타임스탬프 지정 가능
[샘플]
|
Delete delete = new Delete(Bytes.toBytes("row1")); ➊ 특정로우 지정하여 delete 인스턴스생성 delete.setTimestamp(1); ➋ 타임스탬프지정 delete.deleteColumn(Bytes.toBytes("colfam1"), Bytes.toBytes("qual1"), 1); ➌컬럼 하나의 특정 버전을 삭제 delete.deleteColumns(Bytes.toBytes("colfam2"), Bytes.toBytes("qual1")); ➍컬럼 하나의 모든 버전을 삭제 delete.deleteColumns(Bytes.toBytes("colfam2"), Bytes.toBytes("qual3"), 15); ➎컬럼 하나의 특정버젼 및 이전버전 모두삭제 delete.deleteFamily(Bytes.toBytes("colfam3")); ➏ 컬럼패밀리 및 그에 속한 모든 컬럼 및 버전 삭제 delete.deleteFamily(Bytes.toBytes("colfam3"), 3); ➐ 지정된 버전 및 그 이전 버전을 모두 삭제 table.delete(delete); ➑ HBase 테이블에서 데이터 삭제 진행 table.close(); |
2) delete 리스트
- put list 와 유사하게 동작한다.
- 리모트 서버에서는 데이터가 삭제되는 순서를 보장할 수 없다는 것을 명심해야 한다.
- table.delete(deletes) 수행 시 실패한 작업은 deletes에 남게 되며,
Exception 처리는 try/catch 구문을 이용하여 예외처리를 한다.
|
Delete delete4 = new Delete(Bytes.toBytes("row2")); delete4.deleteColumn(Bytes.toBytes("BOGUS"), Bytes.toBytes("qual1")); deletes.add(delete4); try { table.delete(deletes); } catch (Exception e) { System.err.println("Error: " + e); } table.close(); System.out.println("Deletes length: " + deletes.size()); for (Delete delete : deletes) { System.out.println(delete); } |
3) 원자적 확인 후 삭제 연산
- checkAndDelete() 서버측에서 읽은 후 수정 기능 제공
- 동일한 로우에서만 수행 가능함.
3-3. 일괄처리연산 ( batch () )
- delete list, get list 등의 대부분이 batch() 메소드를 기반으로 하고 있어 batch() 권장함
- 동일한 row에 put, delete 연산을 사용하면 각 연산들은 최적성능을 보장하는 순서로 적용 되기 때문에 경합 발생 등의 불안정한 결과를 야기 할 수 있다.
- batch() 메소드 사용시에는 PUT 인스턴스가 클라이언트 쓰기 버퍼에 저장되지 않고
서버에서 직접 처리 된다.
- 일괄처리 메소드
Void batch(actions, results) : 성공한 연산 결과 및 실패한 연산정보 함께 반환
Object[] batch(actions) : 실패 발생하면 아무것도 return 되지 않는다.
3-4. 로우락
- 리전서버는 row locks 기능 제공하여 한 개의 로우에 대한 exclusive lock 가능
- hbase lock 만료기한은 default 1분, hbase-site.xml의 base.regionserver.lease.period 파라미터
- 클라이언트 측에서 lockRow() 명시적인호출 시 unlockRow() 를 통하여 반드시 해제해야 한다.
3-5. SCAN
1) 특성
- SCAN의 경우 HBase 테이블에서 탐색할 시작/종료 로우키를 지정할 수 있다.
- 시작 로우는 탐색에 포함되고 종료 로우는 대상에서 제외된다.
( START ROW KEY =< 스캔대상 < END ROW KEY )
- 시작 로우 KEY가 지정되지 않으면 테이블의 맨 처음에서 시작(ENDKEY 없어도 마지막까지 실행)
- addFamily(), addColumn() 등을 사용하여 지정한 컬럼값만 탐색 스캔범위를 좁히는 역할을 수행
스캔범위 제외된 컬럼은 읽지 않아도 되어 Column based의 장점을 극대화 가능.
2) ResultScanner Class
- 스캔 되어 진 로우들을 RPC로 클라이언트에 전송할때는 로우 단위로 반환된다.
- 스캔된 결과가 아주 큰 경우를 대비하여 ResultScanner를 통하여 각 로우에 대한 Result 인스턴스를 이터레이트 할 수 있도록 감싼 형태이다.
3) 캐싱 vs 일괄처리
- 스캐너캐싱 : 한번의 RPC에서 여러 개의 로우를 전송하는 방식
- 테이블 단위의 캐싱과 스캔단위의 캐싱으로 나뉘어 짐
RDBMS에서 테이블에 DEGREE 적용 VS 쿼리 HINT에 PARALLEL적용 정도의 차이일듯
- 스캐너 캐싱의 최적값은 전송 데이터양과 클라이언트 단의 MAX HEAP 메모리를 검토해야 함
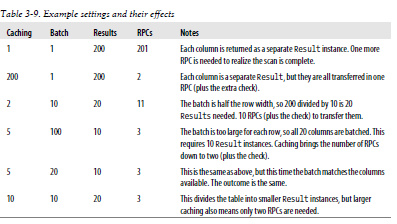
- 일괄처리 : 로우 단위 동작이 아닌 컬럼 단위로 동작 한다.
즉, 일괄처리가 3이면 서버에서 컬럼 3개를 하나의 RESULT 로 묶는다는 얘기이며,
- RPCs = (Rows * Cols per Row) / Min(Cols per Row, Batch size) / Scanner Caching
[샘플]
<?-ml:namespace prefix = v ns = "urn:schemas-microsoft-com:vml" /><?XML:NAMESPACE PREFIX = V />
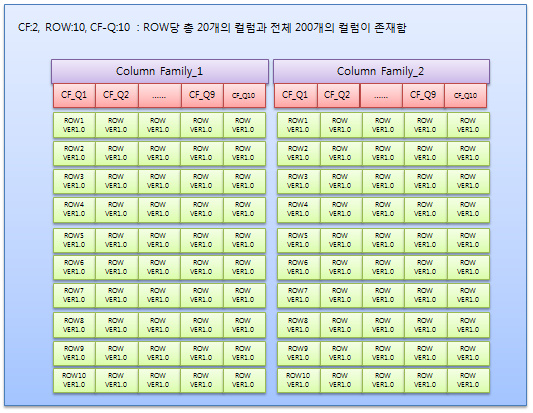
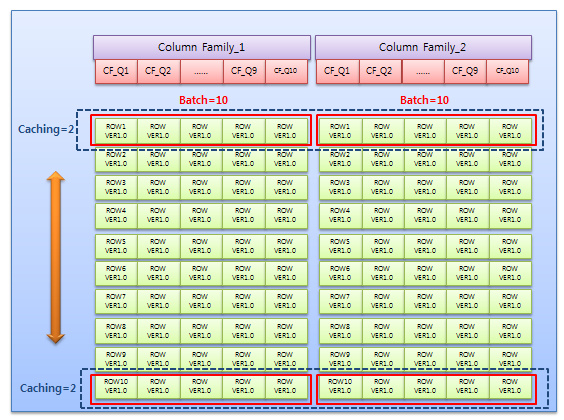
* 샘플 예제를 그림으로 설명하면,
Caching:2, Batch=10 으로 했을 경우 200/10=20 result 20개 필요
RPC = 10번 + Scan 완료를 위한 RPC 1회 추가 = 11회 발생됨