
AI Korea Open 그룹에서도 라이브러리에 관한 투표가 있었고, 많은 분들이 관심있어할 만한 부분이라 생각해서 한 번 정리해 봤습니다!
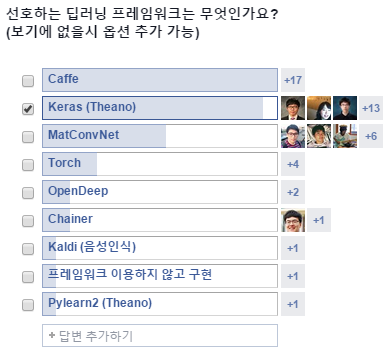 (AI Korea Open 그룹의 투표 결과)
(AI Korea Open 그룹의 투표 결과)
Python
요즘 뜨는 언어답게, 대부분의 라이브러리들이 빠른 속도로 업데이트되며 새로운 기능이 계속 추가되고 있다.
- Theano - 수식 및 행렬 연산을 쉽게 만들어주는 파이썬 라이브러리. 딥러닝 알고리즘을 파이썬으로 쉽게 구현할 수 있도록 해주는데, Theano 기반 위에 얹어서 더 사용하기 쉽게 구현된 여러 라이브러리가 있다.
- Chainer - 거의 모든 딥러닝 알고리즘을 직관적인 Python 코드로 구현할 수 있고, 자유도가 매우 높음. 대다수의 다른 라이브러리들과는 다르게 "Define-by-Run" 형태로 구현되어 있어서, forward 함수만 정의해주면 네트워크 구조가 자동으로 정해진다는 점이 특이하다.
- nolearn - scikit-learn과 연동되며 기계학습에 유용한 여러 함수를 담고 있음.
- Gensim - 큰 스케일의 텍스트 데이터를 효율적으로 다루는 것을 목표로 한 Python 기반 딥러닝 툴킷
- deepnet - cudamat과 cuda-convnet 기반의 딥러닝 라이브러리
- CXXNET - MShadow 라이브러리 기반으로 멀티 GPU까지 지원하며, Python 및 Matlab 인터페이스 제공
- DeepPy - NumPy 기반의 라이브러리
- Neon - Nervana에서 사용하는 딥러닝 프레임워크
Matlab
- MatConvNet - 컴퓨터비젼 분야에서 유명한 매트랩 라이브러리인 vlfeat 개발자인 Oxford의 코딩왕 Andrea Vedaldi 교수와 학생들이 관리하는 라이브러리.
- ConvNet - CNN 라이브러리
- DeepLearnToolbox - DBN, Stacked Autoencoder, CNN 등의 딥러닝을 위한 matlab/octave 툴박스
C++
- Caffe - Berkeley 대학에서 관리하고 있고, 현재 가장 많은 사람들이(추정) 사용하고 있는 라이브러리. C++로 직접 사용할 수도 있지만 Python과 Matlab 인터페이스도 잘 구현되어 있다.
- DIGITS - NVIDIA에서 브라우저 기반 인터페이스로 쉽게 신경망 구조를 구현, 학습, 시각화할 수 있도록 개발한 시스템.
- cuda-convnet - 딥러닝 슈퍼스타인 Alex Krizhevsky와 Geoff Hinton이 ImageNet 2012 챌린지를 우승할 때 사용한 라이브러리
- eblearn - 딥러닝 계의 또하나의 큰 축인 NYU의 Yann LeCun 그룹에서 ImageNet 2013 챌린지를 우승할 때 사용한 라이브러리
- SINGA - 기존의 시스템에서 동작하는 분산처리 학습 알고리즘을 일반적으로 구현하기 위해 만들어진 플랫폼으로 Apache Software Foundation의 후원을 받고 있다.
Java
- ND4J - N-Dimensional Arrays for Java. JVM을 위한 과학 연산 라이브러리로 상용 제품에 사용될 수 있게 연산들이 최소한의 메모리 사용으로 빠르게 작동하게 끔 만들어졌다.
- Deeplearning4j - Java와 Scala로 작성된 첫 상용 수준의 오픈소스 분산처리 딥러닝 라이브러리. 개발툴보다는 business 환경에 적합하도록 작성되었다.
- Encog -머신러닝 프레임워크로 SVM, ANN, Genetic Programming, Genetic Algorithm, Bayesian Network, Hidden Markov Model 등을 지원한다.
JavaScript
자바스크립트로의 딥러닝 구현은 Stanford의 Andrej Karpathy가 혼자서 개발했음에도 불구하고 높은 완성도를 보이며 널리 사용되고 있는 아래 두 라이브러리가 가장 유명하다.
- ConvnetJS - 딥러닝 모델의 학습을 완전히 브라우저에서 할 수 있게 하는 자바스크립트 라이브러리. 별도의 소프트웨어, 컴파일러, 설치, GPU 없이 쉽게 사용할 수 있다.
- RecurrentJS - RNN/LSTM을 구현한 Javascript 라이브러리
Lua
- Torch - 페이스북과 구글 딥마인드에서 사용하는 라이브러리. 양대 대기업에서 사용하고 있는 만큼 필요한 거의 모든 기능이 잘 구현되어 있고, 스크립트 언어인 Lua를 사용하기 때문에 쉽게 사용 가능하다.
Julia
MIT에서 새로 개발한 언어로, 최근에 주목받기 시작하여 효율적인 딥 러닝 라이브러리도 여러 가지 구현되었다.
- Mocha.jl - C++ 프레임워크인 Caffe에 영감을 받아 만들어진 Julia 기반의 딥러닝 프레임워크. Mocha의 General stochastic solver와 공통 레이어를 사용해 deep / shallow(convolutional) neural network를 학습하고 (stacked) auto-encoder를 통해 unsupervised pre-training을 할 수 있다. 모듈화된 구조, 하이 레벨 인터페이스, 이식성, 빠른 속도, 호환성등을 특징으로 한다.
- Strada.jl - Caffe 프레임워크를 기반으로 해 만들어진 오픈소스 딥러닝 라이브러리. CNN과 RNN을 CPU/GPU로 학습할 수 있다.
- KUnet.jl - 최대한 적은 양의 코드로 작성하고자 하는 시도에서 만들어진 딥러닝 패키지. 현재 1000 라인 미만의 코드로 여러 네트워크, activation, optimization을 구현하고 있고, CPU/GPU를 사용해 Caffe와 비슷한 성능으로 학습할 수 있다고 한다.
Lisp
- Lush - Lisp Universal Shell. 대규모 수치, 그래픽 어플리케이션을 위한 객체 지향 프로그래밍 언어. 딥러닝 라이브러리가 머신러닝 라이브러리에 포함되어 제공된다.
Haskell
- DNNGraph - Haskell로 작성된 deep neural network 모델 생성 DSL(domain-specific language)
.NET
- Accord.NET - C#으로만 작성된 .NET 머신러닝 프레임워크로 음성, 이미지 처리 라이브러리가 포함되어 있다. 상용 수준의 컴퓨터 비전, 컴퓨터 음성인식, 신호처리, 통계 어플리케이션을 만들 수 있다.
R
- darch - 레이어가 많은 neural network(deep architecture)를 만들 수 있다. contrastive divergence로 pre-training 하거나 backpropagation, conjugate gradient와 같은 알고리즘을 사용한 fine tuning으로 학습할 수 있다.
- deepnet - BP, RBM, DBN, Deep autoencoder 등의 딥러닝 아키텍쳐, neural network 알고리즘을 구현한 패키지.
출처: http://www.teglor.com/b/deep-learning-libraries-language-cm569/ 블로그 포스트 자료에서 약간의 수정을 거쳤습니다.
작성자: 최명섭, 김주용