Cloudera CDH/CDP 및 Hadoop EcoSystem, Semantic IoT등의 개발/운영 기술을 정리합니다. gooper@gooper.com로 문의 주세요.
1. 아래의 사이트를 참조한다.
http://cafe.naver.com/korlucene
2. github에서 소스를 받아 빌드(goal : install)한다.
https://github.com/korlucene/arirang-analyzer-6
3. build된 *.jar파일을 각노드에 복사
빌드된 arirang.lucene-analyzer-6.2-1.1.0.jar파일과 pom프로젝트의 lib폴더에 있는 arirang-morph-1.1.0.jar파일을 서버에 복사
가. target폴더에 생성된 arirang.lucene-analyzer-6.2-1.1.0.jar파일을 solr가 설치된 폴더의 server/solr-webapp/webapp/WEB-INF/lib에 복사한다.
나. arirang-analyzer-6/lib폴더에 있는 arirang-morph-1.1.0.jar파일을 solr가 설치된 폴더의 server/solr-webapp/webapp/WEB-INF/lib에 복사한다.
가. scp -P 10022 arirang.lucene-analyzer-6.2-1.1.0.jar arirang-morph-1.1.0.jar root@gsda2:$HOME/solr/server/solr-webapp/webapp/WEB-INF/lib/
나. scp -P 10022 arirang.lucene-analyzer-6.2-1.1.0.jar arirang-morph-1.1.0.jar root@gsda3:$HOME/solr/server/solr-webapp/webapp/WEB-INF/lib/
다. scp -P 10022 arirang.lucene-analyzer-6.2-1.1.0.jar arirang-morph-1.1.0.jar root@gsda4:$HOME/solr/server/solr-webapp/webapp/WEB-INF/lib/
3-1. 사용할 collection생성(예시로 제시된 sample_techproducts_configs를 이용하여 gc라는 이름의 컬렉션을 생성함)
$HOME/solr/server/solr/configsets# cp -r sample_techproducts_configs gc
4. $HOME/solr/server/solr/configsset/gc/conf/managed-schema파일에 아래의 내용을 추가(한글 형태소 분석기 사용 설정)
(managed-schema의 위치는 변경될 수 있음, default위치는 $HOME/solr/server/solr/configsets임)
<fieldType name="text_ko" class="solr.TextField"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.ko.KoreanTokenizerFactory"/> <filter class="solr.WordDelimiterFilterFactory"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.ClassicFilterFactory"/> <filter class="org.apache.lucene.analysis.ko.KoreanFilterFactory" hasOrigin="true" hasCNoun="true" bigrammable="false" queryMode="false"/> <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="false" /> <filter class="org.apache.lucene.analysis.ko.WordSegmentFilterFactory" hasOrijin="true"/> <!--filter class="org.apache.lucene.analysis.ko.HanjaMappingFilterFactory"/> <filter class="org.apache.lucene.analysis.ko.PunctuationDelimitFilterFactory"/--> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt"/> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.ko.KoreanTokenizerFactory"/> <filter class="solr.WordDelimiterFilterFactory"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.ClassicFilterFactory"/> <filter class="org.apache.lucene.analysis.ko.KoreanFilterFactory" hasOrigin="true" hasCNoun="true" bigrammable="false" queryMode="false"/> <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="false" /> <filter class="org.apache.lucene.analysis.ko.WordSegmentFilterFactory" hasOrijin="true"/> <filter class="org.apache.lucene.analysis.ko.HanjaMappingFilterFactory"/> <filter class="org.apache.lucene.analysis.ko.PunctuationDelimitFilterFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt"/> </analyzer> </fieldType>
* 특정필드에 적용하고 싶으면 아래와 같이 field의 type를 text_ko로 지정한다
<field name="title" type="text_kor"/>
5. solr를 재시작한다.(bin/solr.in.sh에 SolrCloud관련 설정이 되어있다고 가정함)
bin/solr restart
6.$HOME/solr/server/solr/configsset/gc/conf/managed-schema파일에 아래의 내용을 추가(상품정보를 인덱싱하기 위한 샘플 schema임)
<field name="auc_no" type="string" indexed="true" stored="true" multiValued="true"/>
<field name="cate" type="text_ko" indexed="true" stored="true" multiValued="true"/>
<field name="title" type="text_ko" indexed="true" stored="true" multiValued="true"/>
<field name="contents" type="text_ko" indexed="true" stored="true" multiValued="true"/>
<field name="sel_cnt" type="int" indexed="false" stored="true" multiValued="true"/>
<field name="seller_id" type="string" indexed="true" stored="true" multiValued="true"/>
<field name="seller_name" type="string" indexed="true" stored="true" multiValued="true"/>
<field name="buyer_id" type="string" indexed="true" stored="true" multiValued="true"/>
<field name="buyer_name" type="string" indexed="true" stored="true" multiValued="true"/>
<field name="sel_price" type="float" indexed="true" stored="true" multiValued="true"/>
<field name="auc_price" type="float" indexed="true" stored="true" multiValued="true"/>
<field name="start_date" type="date" indexed="true" stored="true" multiValued="true"/>
<field name="end_date" type="date" indexed="true" stored="true" multiValued="true"/>
<field name="img_url" type="string" indexed="false" stored="true" multiValued="true"/>
7. 생성할 collection(이름 : gc)용 conf정보를 zookeeper에 업로드한다.
$HOME/solr/server/scripts/cloud-scripts# zkcli.sh -z gsda1:2181,gsda2:2181,gsda3:2181 -cmd upconfig -c gc -n gc -d $HOME/solr/server/solr/configsets/gc/conf
8. colleciton(이름: gc)를 생성한다.
bin/solr create -c gc -shards 4 -replicationFactor 2
* collection을 지울때는 : bin/solr delete -c gc
9. 컬렉션 gc에 등록할 데이타를 생성한다(gc_data.csv의 이름으로 생성하고 서버에 올려둔다.)
id,title
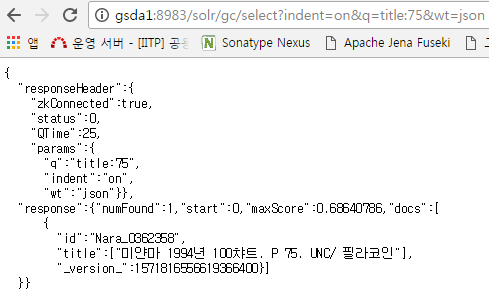
"Nara_0362360","2002, (민트2개팝니다)2002년5원10원흑점있음"
"Nara_0362361","미얀마 1994년 100챠트. P 75. UNC/ 필라코인"
"Nara_0362362","미얀마 1995년 1000챠트. P 75. UNC/ 필라코인"
"Nara_0362363","미얀마1995년1000챠트.P75.UNC/필라코인"
* 파일을 서버에 올리지 말고 solr어드민 화면에서 추가할 수도 있음
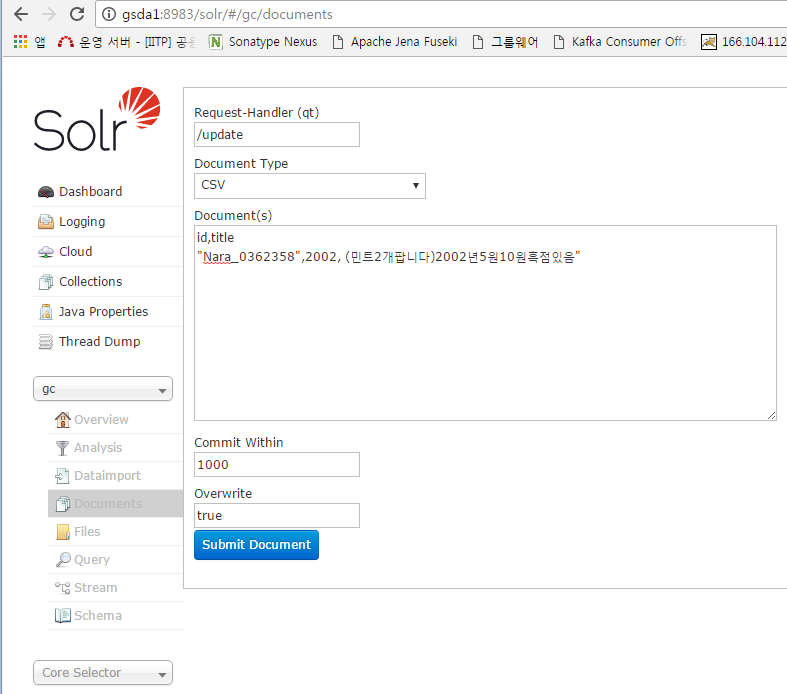
10. 샘플데이타를 gc에 post한다.
root@gsda1:~/solr/bin# post -c gc gc_data.csv
-->콘솔에 보여지는 메세지
/usr/lib/jvm/java-8-oracle/bin/java -classpath /svc/apps/gsda/bin/hadoop/solr/dist/solr-core-6.2.0.jar -Dauto=yes -Dc=gc -Ddata=files org.apache.solr.util.SimplePostTool gc_data.csv
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/solr/gc/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file gc_data.csv (text/csv) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/solr/gc/update...
Time spent: 0:00:00.861
11. 서치쿼리를 수행한다.