
Cloudera CDH/CDP 및 Hadoop EcoSystem, Semantic IoT등의 개발/운영 기술을 정리합니다. gooper@gooper.com로 문의 주세요.
*출처 : http://kysepark.blogspot.kr/2016/08/hbase-write.html
튜닝 결과
먼저 튜닝 결과부터 얘기하겠다.
튜닝 결과 3개의 region server 환경 하에서 최대 초당 30만개의 로그를 HBase에 저장할 수 있었다.
이는 120 바이트 크기의 apache 로그일 경우의 얘기이고 1KB 크기의 netscreen 로그의 경우엔 초당 16만~17만 정도였다.
Apache, sniper, netscreen 세 개의 로그를 소스에서 대략 9만~10만 건을 동시에 전송하여 HBase에 저장할 경우에는 평균 초당 27만~28만 정도가 나왔다.
이는 테이블 한 개 또는 그 이상의 테이블에 데이터를 저장하더라도 결국, 저장할 수 있는 데이터의 총량이 한정되어 있다는 얘기가 될 수 있다. (물론 설정을 통해 더 늘려줄 수는 있을 듯 하나, cloudera manager 자체에서는 리소스 설정에 제한이 되어 있어 그 수준을 더 넘겨서 설정하기는 힘들듯)
하지만 이 정도의 성능을 내기 위해서는 WAL 파일을 쓰지 않도록 설정해야 가능하다. WAL 파일을 쓰지 않게 하면 region server에서 region들간에 충돌이 나거나 하는 문제 발생 시, 복구가 정상적으로 이뤄지지 않게 된다.
WAL 파일을 쓰도록 설정할 경우엔 apache로그로 초당 14만~15만 건 정도를 write할 수 있었다.
위와 같은 성능에 따라 실제 서비스에 적용할 때에는 최대 성능보다는 2~3만 건 이하가 서비스에 적당하다고 생각하고 구성해야 한다.
왜냐하면 HBase에 write 시, memstore에서 flush 발생 또는 compaction이 진행되면 그 영향에 따라 write 되는 로그 건수가 줄어들게 되기 때문이다.
물론, flush나 compaction 뒤에 뒤처진만큼 많이 저장하려고 하지만 HBase 자체에서 처리할 수 있는 최대용량을 넘어서면 지연이 발생하게 된다. (노드를 추가하면 처리 용량을 늘릴 수 있음)
가령, WAL 파일을 쓰게 설정한 환경에서 초당 10만 건 이하로 로그를 수집한다면 문제가 되지 않겠지만 HBase 최대 수집 건수인 14만~15만 건을 수집하려면 데이터 수집에 지연이 발생할 수 있게 된다.
이러한 점을 고려하여 운영을 하는 게 중요하다.
결과에 대해 한 가지 덧붙이자면, 여기에 정리한 설정들을 가지고 이만큼의 결과를 냈지만 이게 최선이랄 수는 없다.
설정 값을 조금 바꾸거나 리소스를 좀 더 늘리거나 한다면 좀 더 나은 결과를 얻을 수도 있을 것이다. 따라서 이러한 설정 값으로 이 정도 성능이 나올 수 있다고 참고하는 수준으로 보면 좋을 듯하다.
환경
Kafka cluster 환경은 'Flume과 Kafka를 사용한 초당 100만개 로그 수집 테스트'에서 설명한 바와 같다.
이번에는 HBase에 데이터를 적재하므로 Kafka cluster의 노드와 같은 서버 3대를 region 서버로 가진 환경에서 테스트가 진행되었다.
따라서 3대의 kafka cluster로부터 데이터를 받아서 3대의 region 서버에 데이터를 저장하는 식으로 HBase 튜닝을 진행하였다.
설정
여기서 default 값은 cloudera manager에서 관리하는 default 값을 의미한다.
그리고 이전에 cloudera 엔지니어가 설정한 값도 있으므로 여기에 포함되어 있지 않은 값도 있을 수 있다.
여기서는 HBase 튜닝에 필요했던 설정 값에 대해서만 다루겠다.
HBase 튜닝 시에는 read를 많이 하느냐 또는 write를 많이 하느냐를 따져서 해당 사용용도에 맞게 튜닝을 해야 한다.
여기서는 write가 많으므로 write를 많이 할 수 있는 설정을 하였다.
HDFS 설정
이름 | default 값 | 설정 값 | 설명 |
|---|---|---|---|
dfs.block.size | 128MiB | 256MiB | HDFS의 블록 크기. 한 개의 WAL 파일이 block 크기로 인해 나눠지지 않게 하기 위함. |
| dfs.datanode.handler.count | 3 | 64 | datanode에서 사용되는 thread 수 |
| dfs.namenode.handler.count | 30 | 64 | namenode에서 사용되는 thread 수 |
| dfs.datanode.max.xcievers | 4096 | 4096 | datanode 내/외로 데이터 전송 시 사용되는 최대 thread 수. |
| dfs.datanode.balance.bandwidthPerSec | 10MB/s | 10MB/s | datanode간 load balancing의 속도 제한. |
HBase pre-split regions
HBase의 region 서버에 데이터를 저장하는데 저장되는 장소를 region이라고 불린다.
이 region을 rowkey를 분할 할당하여 나누어 주지 않으면 한 두 군데의 region에만 데이터를 쓸려고 하는 문제가 발생되어 성능이 저해되는 문제가 있다.
따라서 pre-splitting을 통해 각 region에서는 해당 rowkey를 가진 데이터만 처리하도록 하게 하여 모든 region에서 골고루 데이터를 처리할 수 있도록 한다.
이 부분은 성능에 크게 영향을 미치므로 꼭 해주어야 한다.
ApacheLog, SniperLog, NetScreenLog 테이블을 다음과 같은 hbase shell 명령을 통해 생성하여 region이 분리된 테이블들을 만들었다.
create 'ApacheLog',{NAME=>'cf',TTL=>432000,COMPRESSION=>'SNAPPY'}, SPLITS=>['b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p'] create 'SniperLog',{NAME=>'cf',TTL=>432000,COMPRESSION=>'SNAPPY'}, SPLITS=>['b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p'] create 'NetScreenLog',{NAME=>'cf',TTL=>432000,COMPRESSION=>'SNAPPY'}, SPLITS=>['b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p'] |
|---|
rowkey를 사전순서대로 파악하여 region이 나누어진다.
분할된 region은 다음과 같은 HBase UI 화면에서 확인할 수 있다.

HBase 설정
Read 성능을 증진 시키기 위해서는 HFile 수가 적을 수록 좋다. (즉, 한 개의 파일에 데이터가 많이 들어가 있을수록 좋다)
Write 성능을 증진시키려면 compaction을 적게 할 수록 좋다.
두 가지 모두에 맞게 튜닝을 할 수 없으므로 read 또는 write에 중점을 맞춰서 튜닝을 해야한다.
여기서는 write에 중점을 두어 튜닝을 하였다.
설정에 들어가기 앞서 아래 그림과 같은 방식으로 write가 진행된다는 것을 이해해야 한다.
그리고 HFile은 compaction을 통해 합쳐서 파일의 수를 줄이게 된다. 따라서 이러한 구조를 이해하고 write 성능을 고려해야한다.
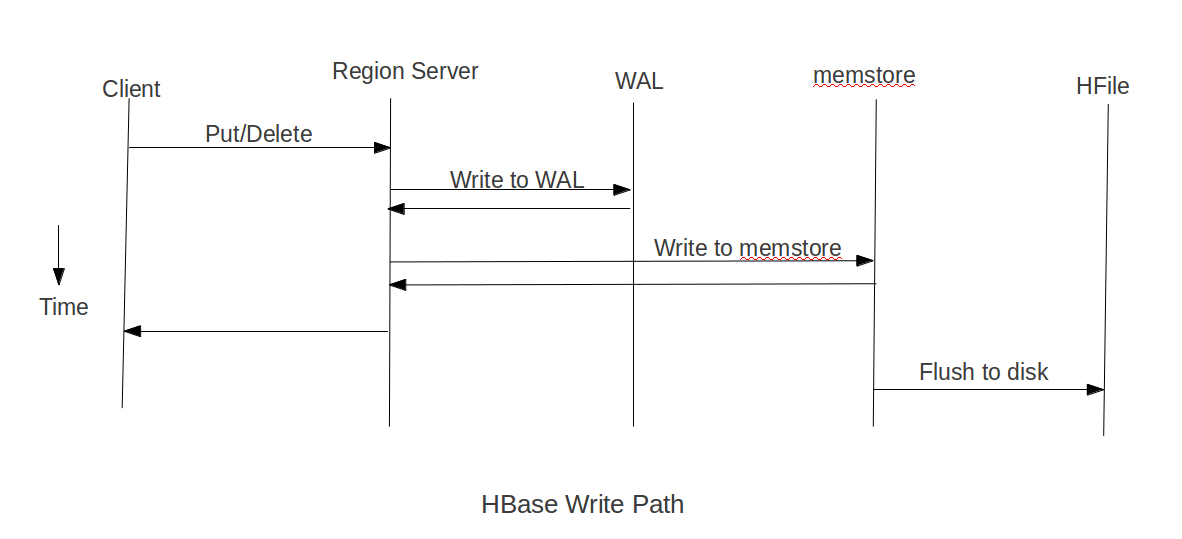
이름 | default 값 | 설정 값 | 설명 |
|---|---|---|---|
| hbase.client.write.buffer | 2MiB | 8MiB | 클라이언트에서 서버로 데이터 전송을 할 때 사용되는 버퍼. 버퍼 크기를 키워서 rpc 횟수를 줄이도록 한다. |
| hbase.regionserver.handler.count | 30 | 100 | region 서버에서 데이터 처리를 위해 사용되는 thread 수. |
| hbase.hregion.memstore.flush.size | 128MiB | 128Mib | MemStore가 이 크기 이상을 가지면 flush가 진행됨. default 값이 좋음. |
| hbase.regionserver.global.memstore.upperLimit | 0.4 | 0.5 | region 서버의 힙영역에서의 MemStore의 크기 비율로 이 크기를 넘기면 MemStore에 쓰기를 차단하고 강제로 flush 하게 됨. 크기가 클 수록 write 성능에 좋음.
|
| hbase.regionserver.global.memstore.lowerLimit | 0.38 | 0.38 | MemStore 크기가 lowLimit에 도달하면 soft한 flush가 발생한다. MemStore에 쓰기를 하면서 flush도 진행함을 의미한다. 예로 MemStore 크기가 힙영역의 38%를 차지하면 soft flush를 발생시킴. |
| hbase.hregion.memstore.block.multiplier | 2 | 8 | MemStore 크기가 'hbase.hregion.block.memstore' 값과 'hbase.hregion.flush.size' 바이트 값을 곱한 값만큼 증가할 경우 쓰기를 차단하고 강제로 flush함. 크기가 클수록 write에 좋음. |
| hbase.hregion.max.filesize | 10MiB | 10MiB | HStoreFile(위 그림에서의 HFile로 생각하면 됨)의 최대 크기입니다. 열 패밀리 HStoreFile 중 하나라도 이 값을 초과하면 호스팅 HRegion이 두 개로 분할된다. default 값이 좋음. |
| hbase.hstore.blockingStoreFiles | 10 | 200 | 한 HStore에 이 수보다 많은 HStoreFile이 있을 경우, 압축이 완료될 때까지 또는 'hbase.hstore.blockingWaitTime'에 지정된 값이 초과될 때까지 이 HRegion에 대한 업데이트가 차단된다. 값이 클수록 write 성능에 좋음. |
| hfile.block.cache.size | 0.4 | 0.3 | HFile/StoreFile에서 사용하는 블록 캐시에 할당할 최대 힙(-Xmx 설정)의 백분율이다. 해제하려면 이 값을 0으로 설정하면 된다. write 성능을 향상 시키기 위해 값을 줄이고 hbase.regionserver.global.memstore.upperLimit을 늘려주는 게 좋다. |
| hbase.hstore.compactionThreshold | 3 | 3 | 이 HStoreFile 수를 초과하는 HStore가 하나라도 있으면 압축이 실행되어 모든 HStoreFile 파일을 하나의 HStoreFile로 다시 씁니다. 이 값이 클수록 압축으로 인한 시간 지연이 발생한다. |
| hbase.hregion.majorcompaction | 7일 | 7일 | 주기적으로 하나의 region에서 여러개의 HStoreFile들을 하나의 파일로 압축하는 일을 한다. 되도록이면 서비스 이용 시간이 적은 시간대에 이뤄지는게 좋음. (본 튜닝 테스트에서는 이 부분에 대해서 고려하지 않았음.) |
| HBase RegionServer의 Java 힙 크기 | 4GiB | 32GiB | region 서버에서 사용할 힙 크기. |
위와 같은 설정들을 보면 HBase 튜닝하는 게 어려운 일이라는 것을 알 수 있다.
그리고 위 설정들의 튜닝으로 성능을 어느 정도 올린 이후에는 write 성능의 경우, flush와 compaction이 서비스에 영향을 주지 않을 정도로 부드럽게 이뤄지도록 조정해주어야 한다.
가령, 이런 문제가 발생할 수 있다. MemStore 크기가 커져서 flush를 하려는데 지금 존재하고 있는 HStoreFile의 수가 많아(blockingStoreFiles 설정에 따라 flush 막음) flush를 하지 못하게 될 수 있다. 이러면 장애가 발생한다.
또는 flush 크기가 너무 크거나 compaction하는 파일들의 크기가 커서 지연이 발생할 수 있다.
또한 region의 크기가 너무 커지면 자동으로 region을 분할하게 된다. 이렇게 분할되는 region이 많을수록 성능에 문제가 있을 수 있다. 따라서 수집하는 데이터 양이 많다면 hbase.hregion.max.filesize 크기 설정을 적절하게 키워주는 게 좋다.
서비스는 24/7 이뤄져하므로 이러한 일들도 고려해야 한다.
Flume 설정
Flume 구성은 다음 블로그 내용에서와 같이 하였다.
그림으로 보면 아래와 같다.
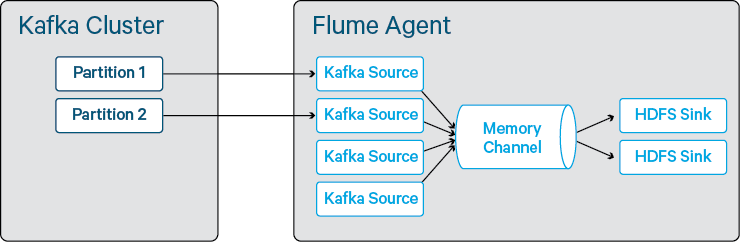
위 그림에서 HDFS Sink를 HBase Sink를 사용했다는 점이 다르다.
실제 flume 설정 내용은 다음과 같다. (HBase sink 성능을 내기 위해서 WAL 파일을 쓰지 않게 했다.)
설정에서 사용된 KafkaSource는 kafka 파티션 키를 설정하여 해당 파티션으로부터 데이터를 받을 수 있게 수정된 버전이다.
HBase sink에서 사용되는 PreSplittedEventSerializer는 pre-split 된 테이블에 맞게 rowkey 맨 앞에 설정한 값을 넣어서 rowkey를 만들도록 구현하였다.
tier3.sources = apache_src1 apache_src2 apache_src3 apache_src4 apache_src5 apache_src6 apache_src7 apache_src8 apache_src9 apache_src10 sniper_src1 sniper_src2 sniper_src3 sniper_src4 sniper_src5 sniper_src6 sniper_src7 sniper_src8 sniper_src9 sniper_src10 netscreen_src1 netscreen_src2 netscreen_src3 netscreen_src4 netscreen_src5 netscreen_src6 netscreen_src7 netscreen_src8 netscreen_src9 netscreen_src10 tier3.sinks = apache_sink1 apache_sink2 apache_sink3 apache_sink4 sniper_sink1 sniper_sink2 sniper_sink3 sniper_sink4 netscreen_sink1 netscreen_sink2 netscreen_sink3 netscreen_sink4 tier3.channels = apache_ch1 netscreen_ch1 sniper_ch1 # Apache Log Source tier3.sources.apache_src1.type = com.igloosec.flume.source.kafka.KafkaSource tier3.sources.apache_src1.channels = apache_ch1 tier3.sources.apache_src1.zookeeperConnect = mn1.igloosecurity.co.kr:2181,mn2.igloosecurity.co.kr:2181,mn3.igloosecurity.co.kr:2181 tier3.sources.apache_src1.topic = ApacheLog tier3.sources.apache_src1.batchSize = 8000 tier3.sources.apache_src1.key = 0 tier3.sources.apache_src1.groupId = ApacheLogConsumerHDFS tier3.sources.apache_src1.kafka.socket.receive.buffer.bytes=16777216 ...... tier3.sources.apache_src10.type = com.igloosec.flume.source.kafka.KafkaSource tier3.sources.apache_src10.channels = apache_ch1 tier3.sources.apache_src10.zookeeperConnect = mn1.igloosecurity.co.kr:2181,mn2.igloosecurity.co.kr:2181,mn3.igloosecurity.co.kr:2181 tier3.sources.apache_src10.topic = ApacheLog tier3.sources.apache_src10.batchSize = 8000 tier3.sources.apache_src10.key = 9 tier3.sources.apache_src10.groupId = ApacheLogConsumerHDFS tier3.sources.apache_src10.kafka.socket.receive.buffer.bytes=16777216 # Apache Log HBase sink tier3.sinks.apache_sink1.channel = apache_ch1 tier3.sinks.apache_sink1.type = asynchbase tier3.sinks.apache_sink1.zookeeperQuorum = mn1.igloosecurity.co.kr:2181,mn2.igloosecurity.co.kr:2181,mn3.igloosecurity.co.kr:2181 tier3.sinks.apache_sink1.table = ApacheLog tier3.sinks.apache_sink1.columnFamily = cf tier3.sinks.apache_sink1.serializer = com.igloosec.flume.sink.hbase.PreSplittedEventSerializer tier3.sinks.apache_sink1.serializer.rowPrefixes=a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p tier3.sinks.apache_sink1.batchSize=3000 tier3.sinks.apache_sink1.enableWal=false ...... tier3.sinks.apache_sink4.channel = apache_ch1 tier3.sinks.apache_sink4.type = asynchbase tier3.sinks.apache_sink4.zookeeperQuorum = mn1.igloosecurity.co.kr:2181,mn2.igloosecurity.co.kr:2181,mn3.igloosecurity.co.kr:2181 tier3.sinks.apache_sink4.table = ApacheLog tier3.sinks.apache_sink4.columnFamily = cf tier3.sinks.apache_sink4.serializer = com.igloosec.flume.sink.hbase.PreSplittedEventSerializer tier3.sinks.apache_sink4.serializer.rowPrefixes=a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p tier3.sinks.apache_sink4.batchSize=3000 tier3.sinks.apache_sink4.enableWal=false # Use a channel which buffers events in memory tier3.channels.apache_ch1.type = memory tier3.channels.apache_ch1.capacity = 100000 tier3.channels.apache_ch1.transactionCapacity = 15000 # Sniper Log Source tier3.sources.sniper_src1.type = com.igloosec.flume.source.kafka.KafkaSource tier3.sources.sniper_src1.channels = sniper_ch1 tier3.sources.sniper_src1.zookeeperConnect = mn1.igloosecurity.co.kr:2181,mn2.igloosecurity.co.kr:2181,mn3.igloosecurity.co.kr:2181 tier3.sources.sniper_src1.topic = SniperLog tier3.sources.sniper_src1.batchSize = 8000 tier3.sources.sniper_src1.key = 0 tier3.sources.sniper_src1.groupId = ApacheLogConsumerHDFS tier3.sources.sniper_src1.kafka.socket.receive.buffer.bytes=16777216 ...... tier3.sources.sniper_src10.type = com.igloosec.flume.source.kafka.KafkaSource tier3.sources.sniper_src10.channels = sniper_ch1 tier3.sources.sniper_src10.zookeeperConnect = mn1.igloosecurity.co.kr:2181,mn2.igloosecurity.co.kr:2181,mn3.igloosecurity.co.kr:2181 tier3.sources.sniper_src10.topic = SniperLog tier3.sources.sniper_src10.batchSize = 8000 tier3.sources.sniper_src10.key = 9 tier3.sources.sniper_src10.groupId = ApacheLogConsumerHDFS tier3.sources.sniper_src10.kafka.socket.receive.buffer.bytes=16777216 # Sniper Log HBase sink tier3.sinks.sniper_sink1.channel = sniper_ch1 tier3.sinks.sniper_sink1.type = asynchbase tier3.sinks.sniper_sink1.zookeeperQuorum = mn1.igloosecurity.co.kr:2181,mn2.igloosecurity.co.kr:2181,mn3.igloosecurity.co.kr:2181 tier3.sinks.sniper_sink1.table = SniperLog tier3.sinks.sniper_sink1.columnFamily = cf tier3.sinks.sniper_sink1.serializer = com.igloosec.flume.sink.hbase.PreSplittedEventSerializer tier3.sinks.sniper_sink1.serializer.rowPrefixes=a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p tier3.sinks.sniper_sink1.batchSize=3000 tier3.sinks.sniper_sink1.enableWal=false ...... tier3.sinks.sniper_sink4.channel = sniper_ch1 tier3.sinks.sniper_sink4.type = asynchbase tier3.sinks.sniper_sink4.zookeeperQuorum = mn1.igloosecurity.co.kr:2181,mn2.igloosecurity.co.kr:2181,mn3.igloosecurity.co.kr:2181 tier3.sinks.sniper_sink4.table = SniperLog tier3.sinks.sniper_sink4.columnFamily = cf tier3.sinks.sniper_sink4.serializer = com.igloosec.flume.sink.hbase.PreSplittedEventSerializer tier3.sinks.sniper_sink4.serializer.rowPrefixes=a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p tier3.sinks.sniper_sink4.batchSize=3000 tier3.sinks.sniper_sink4.enableWal=false # Use a channel which buffers events in memory tier3.channels.sniper_ch1.type = memory tier3.channels.sniper_ch1.capacity = 100000 tier3.channels.sniper_ch1.transactionCapacity = 15000 # NetScreen Log Source tier3.sources.netscreen_src1.type = com.igloosec.flume.source.kafka.KafkaSource tier3.sources.netscreen_src1.channels = netscreen_ch1 tier3.sources.netscreen_src1.zookeeperConnect = mn1.igloosecurity.co.kr:2181,mn2.igloosecurity.co.kr:2181,mn3.igloosecurity.co.kr:2181 tier3.sources.netscreen_src1.topic = NetScreenLog tier3.sources.netscreen_src1.batchSize = 8000 tier3.sources.netscreen_src1.key = 0 tier3.sources.netscreen_src1.groupId = ApacheLogConsumerHDFS tier3.sources.netscreen_src1.kafka.socket.receive.buffer.bytes=16777216 ...... tier3.sources.netscreen_src10.type = com.igloosec.flume.source.kafka.KafkaSource tier3.sources.netscreen_src10.channels = netscreen_ch1 tier3.sources.netscreen_src10.zookeeperConnect = mn1.igloosecurity.co.kr:2181,mn2.igloosecurity.co.kr:2181,mn3.igloosecurity.co.kr:2181 tier3.sources.netscreen_src10.topic = NetScreenLog tier3.sources.netscreen_src10.batchSize = 8000 tier3.sources.netscreen_src10.key = 9 tier3.sources.netscreen_src10.groupId = ApacheLogConsumerHDFS tier3.sources.netscreen_src10.kafka.socket.receive.buffer.bytes=16777216 # NetScreen Log HBase sink tier3.sinks.netscreen_sink1.channel = netscreen_ch1 tier3.sinks.netscreen_sink1.type = asynchbase tier3.sinks.netscreen_sink1.zookeeperQuorum = mn1.igloosecurity.co.kr:2181,mn2.igloosecurity.co.kr:2181,mn3.igloosecurity.co.kr:2181 tier3.sinks.netscreen_sink1.table = NetScreenLog tier3.sinks.netscreen_sink1.columnFamily = cf tier3.sinks.netscreen_sink1.serializer = com.igloosec.flume.sink.hbase.PreSplittedEventSerializer tier3.sinks.netscreen_sink1.serializer.rowPrefixes=a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p tier3.sinks.netscreen_sink1.batchSize=3000 tier3.sinks.netscreen_sink1.enableWal=false ...... tier3.sinks.netscreen_sink4.channel = netscreen_ch1 tier3.sinks.netscreen_sink4.type = asynchbase tier3.sinks.netscreen_sink4.zookeeperQuorum = mn1.igloosecurity.co.kr:2181,mn2.igloosecurity.co.kr:2181,mn3.igloosecurity.co.kr:2181 tier3.sinks.netscreen_sink4.table = NetScreenLog tier3.sinks.netscreen_sink4.columnFamily = cf tier3.sinks.netscreen_sink4.serializer = com.igloosec.flume.sink.hbase.PreSplittedEventSerializer tier3.sinks.netscreen_sink4.serializer.rowPrefixes=a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p tier3.sinks.netscreen_sink4.batchSize=3000 tier3.sinks.netscreen_sink4.enableWal=false # Use a channel which buffers events in memory tier3.channels.netscreen_ch1.type = memory tier3.channels.netscreen_ch1.capacity = 100000 tier3.channels.netscreen_ch1.transactionCapacity = 15000 |
|---|