
Authorization With Apache Sentry
2018.03.05 22:08
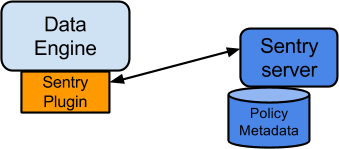
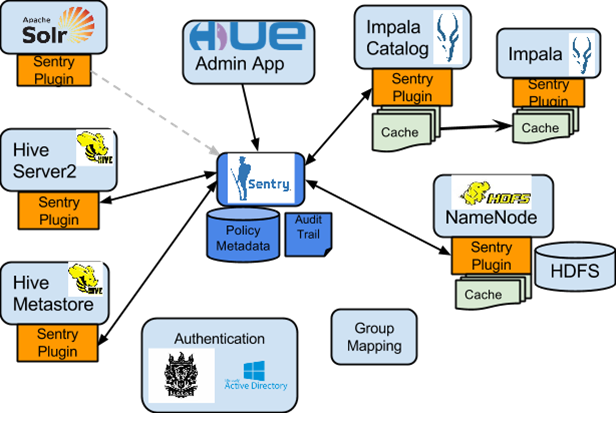
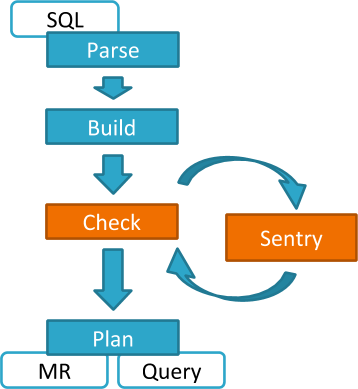
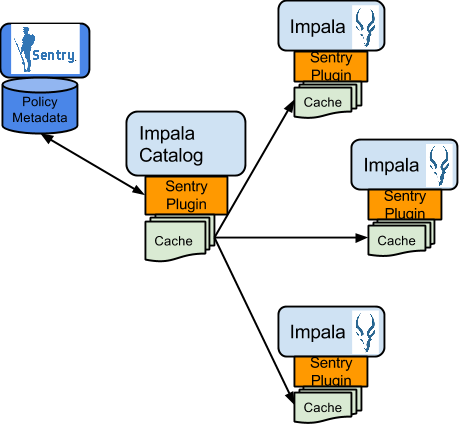
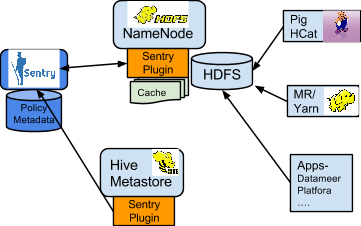
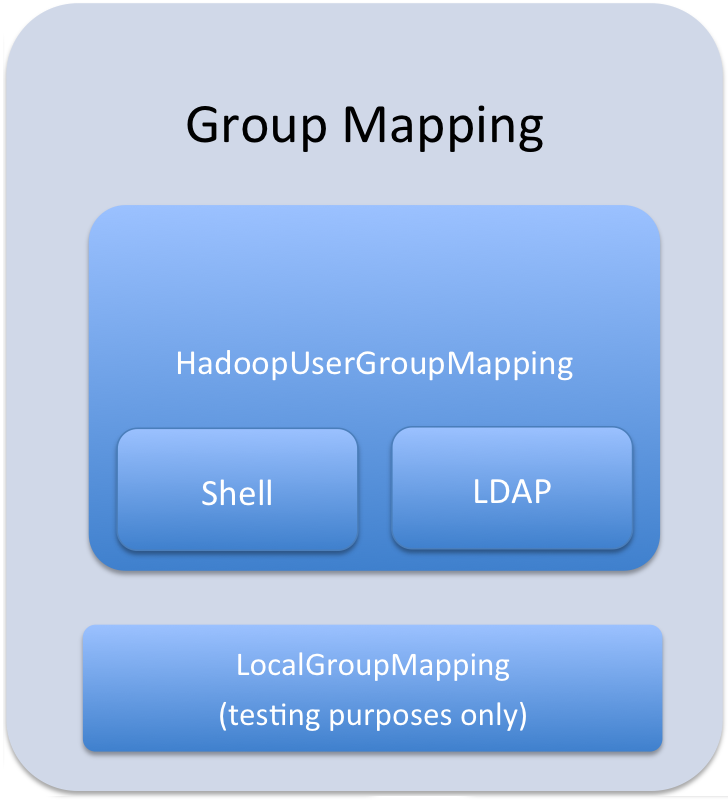
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 11 | https://docs.cloudera.com/cdp-private-cloud-base/7.1.6/security-overview/topics/cm-security-authentication-overview.html | gooper | 2022.06.07 | 859 |
| 10 | 약관 | 총관리자 | 2021.12.31 | 215 |
| 9 | Docker+Kubernetes를 이용한 빌드 서버 가상화 사례 SK플래닛@tech세미나 | 총관리자 | 2019.06.07 | 5051 |
| 8 | ssd문의 | 총관리자 | 2019.05.27 | 5 |
| 7 | 2014년 까지의 동전 발행량 | 총관리자 | 2018.11.18 | 23 |
| 6 |
Sentry 설치하기
| 총관리자 | 2018.03.05 | 15 |
| » |
Authorization With Apache Sentry
| 총관리자 | 2018.03.05 | 11 |
| 4 |
그립에서 얘기하는 리소스 구조
| 총관리자 | 2017.06.07 | 47 |
| 3 | uauction 메세지 파일 번역하기위한 jsp파일 | 총관리자 | 2017.05.30 | 7056 |
| 2 | 메세지 파일 | 총관리자 | 2017.05.30 | 121131 |
| 1 |
test note images
| 총관리자 | 2017.04.06 | 47 |